When we tell people that a 12-person infrastructure team handles over $2B in annual transaction volume, the first question is usually about headcount. How do you scale incident response with that few people? What happens when something breaks at 3am?
Those are fair questions. But they're also the wrong place to start. The reason we can operate at that ratio isn't because our team works harder or longer — it's because the architecture does most of the operational work that would otherwise require human intervention.
What the team actually does
Twelve people covering $2B in transaction volume sounds thin until you understand what those twelve people are responsible for. Six are focused entirely on building and improving the payment infrastructure that our platform customers use. Three handle reliability engineering — building the tooling, runbooks, and automation that keeps everything running. Two focus on compliance and security. One manages integrations with our banking partners and processor network.
What none of these people are doing is manually reviewing transactions, manually reconciling settlement files, or manually handling routine operational issues. Those are automated. The human judgment goes into exception handling, capacity planning, and making the systems smarter over time.
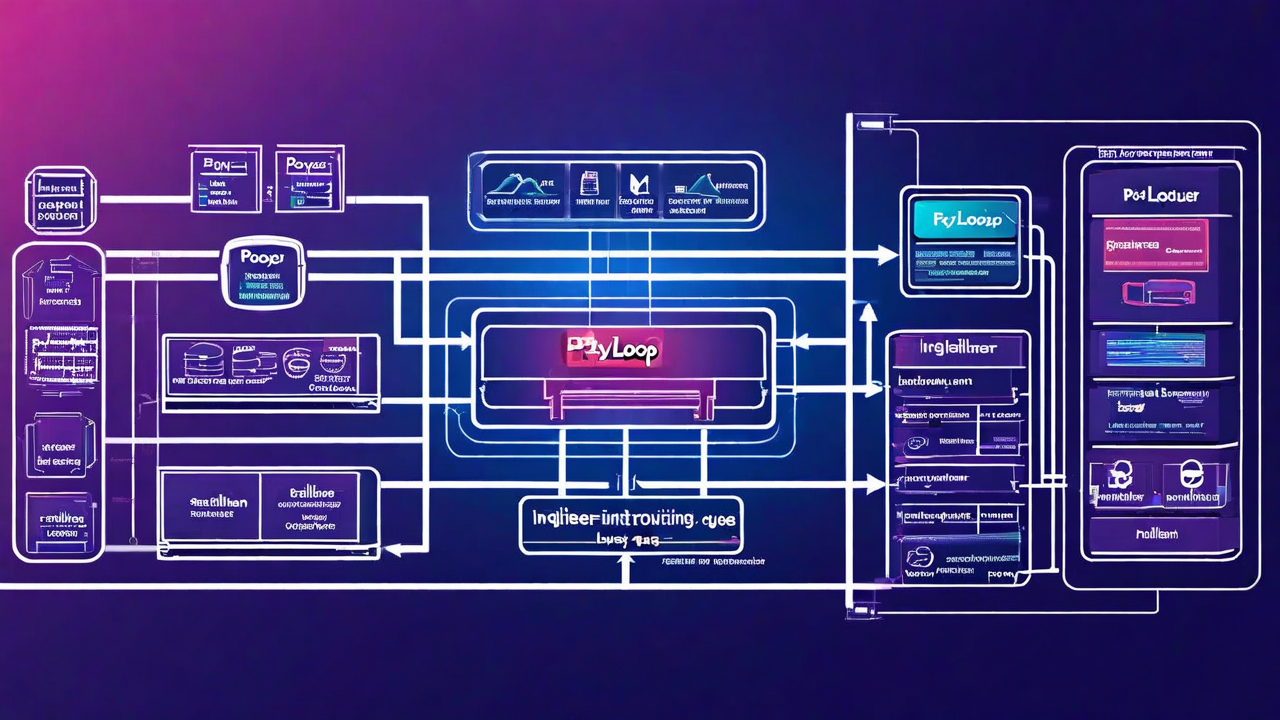
The routing layer: where most of the operational complexity lives
Our transaction routing layer is the most heavily engineered part of the stack. It sits between inbound payment requests and our downstream processor connections, and it does a significant amount of work on every transaction.
For each incoming charge, the router evaluates: issuing bank BIN ranges to determine card type and likely approval rates by processor, current processor health (success rates, latency percentiles, and whether any processors are in a degraded state), transaction characteristics (amount, currency, merchant category code), and customer history (is this a known good account with established patterns, or a new account that looks unusual?).
This evaluation happens in under 50ms and produces a ranked list of processors to attempt the transaction against. The routing weights update automatically based on real-time success rate data — we're not manually tuning these on a weekly basis. The system learns which routes work better for which transaction types and adjusts accordingly.
The practical effect: our approval rate runs 4–6 percentage points higher than what most platforms see on single-processor integrations. On $2B in volume, a 5% improvement in approval rate is $100M in recovered revenue for our customers that would otherwise have been declined.
Event-driven settlement: eliminating the batch job problem
Traditional payment processing runs on batch jobs. End of day, a file is generated, sent to the acquiring bank, and settlement happens the following business day. This model creates two problems: settlement finality is always delayed, and errors discovered in the batch don't surface until after the file has already been sent.
Our settlement pipeline is event-driven. When a transaction is authorized, a settlement event is queued immediately. Settlement workers process these events in near-real-time, grouping them into settlement batches by processor and currency as they accumulate. The batch composition logic handles cut-off times, minimum batch sizes, and the specific requirements of each acquiring bank — all without manual configuration per batch run.
This matters operationally because problems are discovered at the event level, not the batch level. A transaction that fails to settle (usually due to a downstream banking issue) generates an alert immediately, not at end-of-day reconciliation. Our team sees failures as they happen rather than discovering a reconciliation gap the next morning.
Settlement lag — the time between authorization and settlement initiation — runs under four hours for most transactions. For our highest-volume customers, we've reduced this to under 90 minutes for standard card volume. Banks still determine final settlement timing, but we're not adding delay on our end.
Reconciliation: the problem most companies underinvest in
Reconciliation is where payment operations teams spend most of their time at companies that haven't automated it. Matching authorized transactions against settled amounts, handling partial settlements, dealing with reversals that arrive days after the original transaction — this is tedious, error-prone work when done manually.
We built a reconciliation engine that handles three-way matching: transaction records from our database against settlement confirmations from processors against funding records from our banking partners. Every discrepancy is flagged automatically with context — why we think it occurred and what action is needed to resolve it.
About 97% of transactions reconcile automatically without any human review. The remaining 3% go into a work queue with full context attached. Our reconciliation analyst typically clears that queue in under two hours per day. For $2B annually — roughly 8–10 million transactions per year — that's a very manageable exception volume.
On-call structure for a small team
With a 12-person team, on-call rotation is thin. Each person is on-call roughly one week in six, and the expectation is that on-call means handling alerts that the automation can't self-resolve — not babysitting dashboards all night.
Our alerting is tiered: P1 pages immediately (processor outage, settlement pipeline stopped, fraud rate spike above threshold). P2 wakes people up if it persists more than 15 minutes. P3 goes into the next morning's queue. The vast majority of overnight issues are P3 — they're handled in the morning without anyone losing sleep.
The thing that makes this work is runbooks that are actually maintained. When an on-call engineer gets a P1 page at 2am, the runbook for that alert covers exactly what happened last time, what was tried, and what resolved it. Tribal knowledge doesn't help at 2am — documented, searchable procedures do.
What this means for platform customers
The architecture we built for ourselves is what we expose to platform customers via the API. When you integrate PayLoop, you're not getting a thin API wrapper around a single processor — you're getting the routing logic, the event-driven settlement pipeline, and the reconciliation automation that runs our own $2B operation.
That's the actual value of a payment infrastructure API: you shouldn't have to build and maintain this machinery yourself. Your team's time is worth more than rebuilding routing logic and reconciliation pipelines from scratch.
Infrastructure built for scale, ready for your platform
The same routing, settlement, and reconciliation logic powering our $2B annual volume is available via API.
Get API Keys